In a recent article published by OpenAI, they showed off their shiny new open-source bench marking tool christened SimpleQA. While the tool itself seems pretty useful as far as large language models go (being able to test for correctness of answers, covering a large diversity of topics, being designed around the most modern models, and having nice UX overall) there was a charts that they used to show off its capabilities that caught my eye.
The Given Chart and Its Errors
This was the chart given to show off how each major OpenAI language model performed using the new SimpleQA tool.
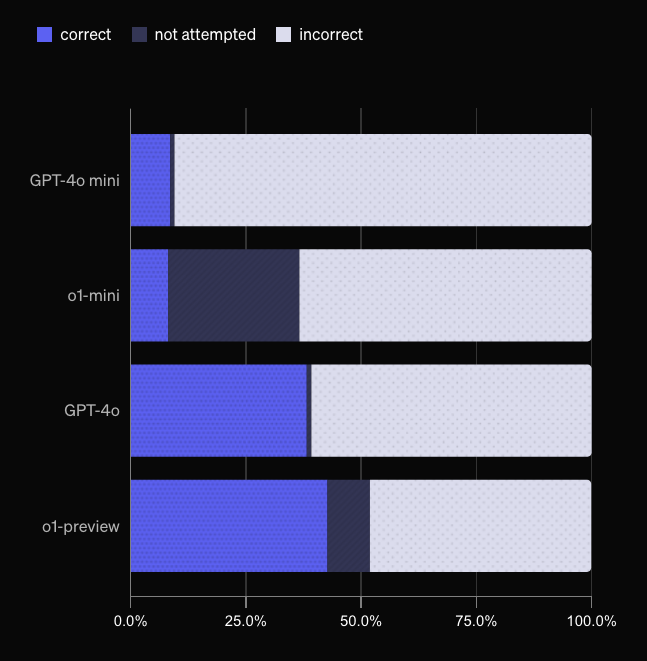
The interesting thing here is that the tool seems to have worked well and produced useful data, but it's the display of the data (and the implications they are trying to make about their lineup) that are a bit troubling.
The first thing I noticed was that the "Not Attempted" portion was a deep navy, while the correct portion was a strong blue. While there's nothing blatantly nefarious about this, I find it strange to categorize answers like "I do not know the answer to that question" and "please browse the internet yourself for that answer" as being closer to correct than incorrect. Visually at a glance it seems to imply the models are doing better than they should be.
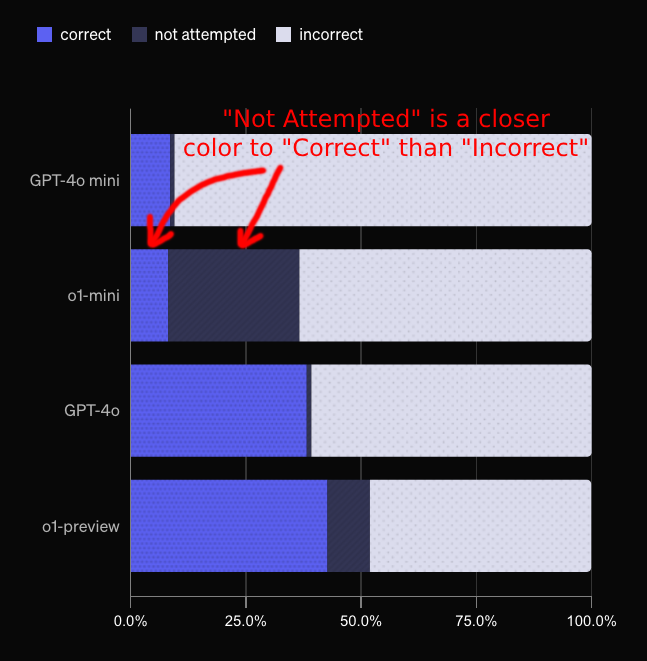
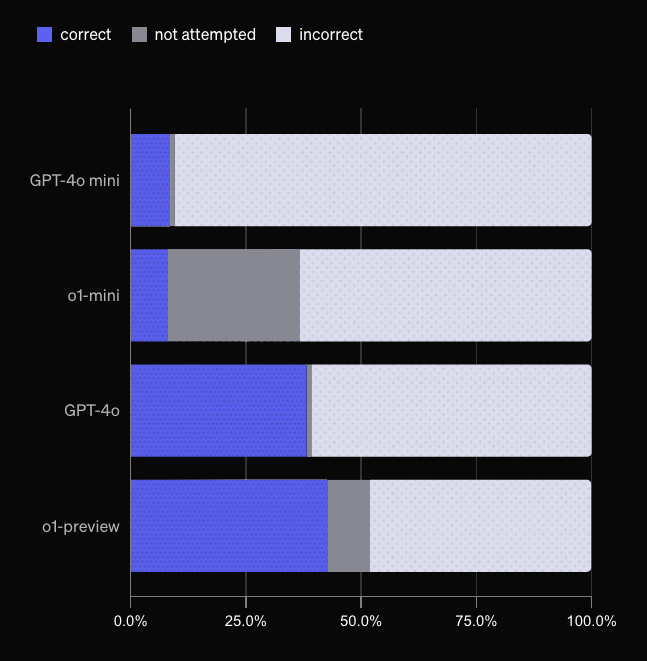
If we change that to gray you can notice two things:
- The
o1models are not that much better than theGPT-4omodels in terms of giving correct answers - The trend of "every model getting significantly better" isn't as strong
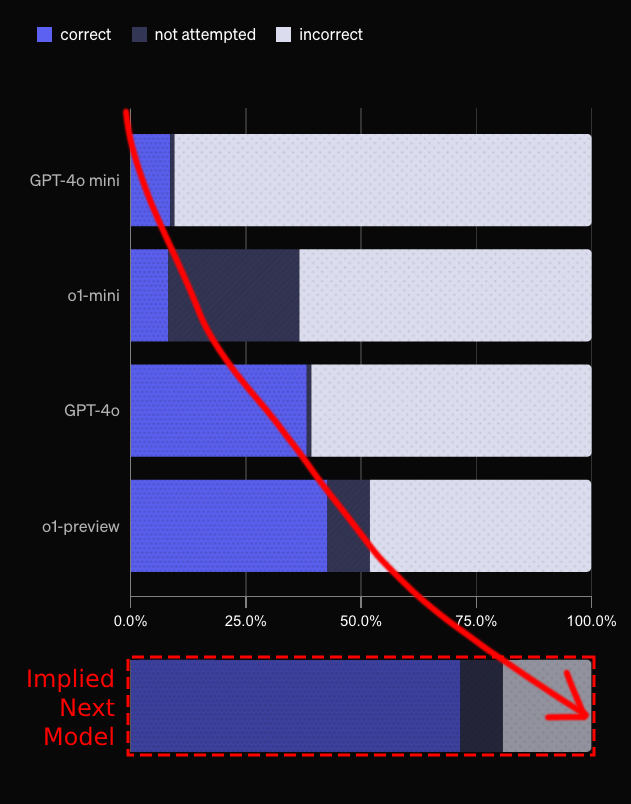
Speaking of trends, ordering the bars in this way creates a lot of visual implications. Since the bars increase slightly each time they imply almost an exponential curve. Because of this, our brains fill in the "Next Model", and that it must be another large leap ahead instead of another incremental upgrade because that's how the trend line is moving.
Fixing The Chart with ZingChart
To fix this we can start back with the original data and chart. I've recreated it in ZingChart so that we're able make some tweaks to it a little easier.
Changing the "Not Attempted" category to a more neutral color as we showed earlier helps and is a simple hex color swap.
Putting the bars side-by-side and arranging them so that "Correct" and "Incorrect" are next to each other better shows that there isn't a model that is more often correct than incorrect. It also makes it easier to see how many times greater one is than the other.
Our next step is to make it clear which outcomes were desired and which weren't, I've changed "Incorrect" to red, "Not Attempted" to pink, and "Correct" to green. Seeing a mostly red circle is much more impactful than seeing a small blue slice, though they are showing the same data.
Though if what we're really after is viewing the relationship of parts to a whole, there's a chart type designed just for that - the Pie Chart. The final change to make then is changing the chart type to pie helps give us at-a-glance quick proportions of slices as we can quickly intuit how big 25%, 50%, and 75% is.
Final Thoughts
Designing a chart requires a lot of decisions to be made, conscious or not. The exact same data can be displayed to tell many different stories. While I am not saying with certainty that OpenAI's chart was meant to deceive, it definitely did attempt to soften the blow of what the raw data showed. While viewing data visualizations with a critical eye takes some skills that have be honed, it is important in getting the full story of what the data is actually saying.